1st Iteration (Streamlit)¶
Streamlit 기반 간단 웹 인터페이스를 구축하여 점역 기능을 시연했습니다. 사용자는 텍스트 혹은 문서를 업로드하고, 결과를 웹 화면, 혹은 BRL/BRF 파일로 다운로드 받을 수 있었습니다.
-
주요 구현:
- FastAPI 백엔드 서버 + Streamlit 프론트엔드
- T5, Llama 중 모델을 선택하여 Deploy 가능하도록 구현
- Docker Compose를 통한 컨테이너화
-
성과:
- 목표로 했던 속도를 갖춘 점역 정확도를 달성
- 성능을 빠르게 확인해 볼 수 있는 환경을 구축
Architecture¶
Initial Design¶
graph LR
A[User]
B(Streamlit)
C(Splitter)
D(Merger)
E(FastAPI)
F{"Model<br>T5 or Llama"}
subgraph Frontend
A
B
end
subgraph Pre/PostProcess
C
D
end
subgraph Inference
E
F
end
B~~~D
D~~~E
A-->|Upload| B
B-->|Download| A
B-->|Full Text| C
C-->|Send Text Parts| E
E-->|Inference| F
F-->|Result| E
E-->|Send Braille Parts| D
D-->|Merge Brailles| BFinal Design¶
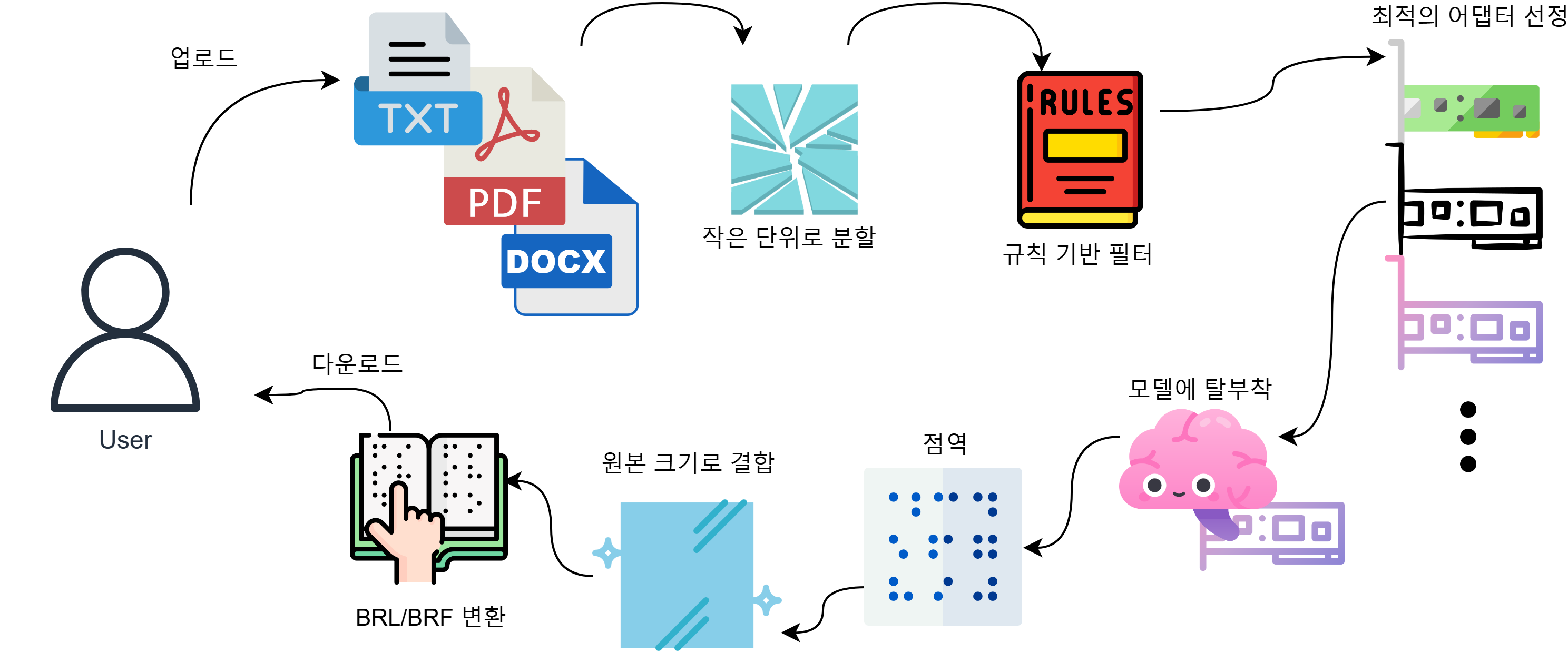
변경 사항¶
- BRL/BRF 파일로 다운로드 받을 수 있도록 구현
- 적은 비용으로 맞춤형 점역이 가능하도록 어댑터 사용 구조를 구현
사용자의 업로드¶
업로드는 두가지로 구분하였습니다.
- 웹UI를 통한 직접 입력: 텍스트 입력 후 POST 합니다.
- 파일 업로드: PDF나 텍스트 파일을 업로드합니다.
FastAPI로의 전달¶
- 직접 입력인 경우, 혹은 텍스트 파일인 경우: 적정 길이로 잘라서 전달합니다.
- PDF인 경우: 외부 라이브러리를 통해 텍스트로 변환 수 전달합니다.
모델 추론¶
train된 모델을 모두 huggingface에 public으로 업로드 하였으므로 모델은 T5와 Llama 중 선택하여 사용할 수 있습니다.
빠른 교정이 필요한 경우를 위해, T5 사용시 문구의 내용에 따라 어댑터를 사용할 수 있도록 구현하였습니다.
나누기와 합치기¶
너무 긴 문장은 처리가 불가하여 아예 결과를 얻지 못하므로 문장 단위로 나누어 전달합니다.
점역된 결과를 다시 하나로 합치고, BRF 포맷을 원하는 경우 BRF로 변환하여 다운로드 받을 수 있도록 했습니다.
상세¶
PDF를 업로드 할 수 있어야 한다.¶
개발 의도에 따라, 교재로 사용하는 책의 내용을 점자로 변환할 수 있어야 합니다. 대부분의 스캔본은 PDF로 제공되고 논문등도 마찬가지이므로 PDF를 업로드해 점역 결과물을 얻을 수 있도록 개발이 진행되었습니다.
PDF는 내부에 텍스트로 있을 수도 있고, 이미지로만 있을 수 있으나 외부 라이브러리가 높은 인식률을 보이고 있어 그대로 텍스트로 취급해도 무방하였습니다.
단 외부 라이브러리를 사용한다는 점, 그리고 도형이나 그래프, 표등의 텍스트가 아닌 부분은 제대로 인식되지 않았습니다. 그러나 이는 Vision 모델을 추가하지 않는 한 해결하기 어려운 사항이며, 병렬로 진행하기 어려운 과제입니다. 따라서 본 프로젝트에서는 이를 고려하지 않았습니다.
다만 추후 deploy하는 측에서 필요에 따라 Vision 모델을 추가해 서비스에 포함시킬 수 있도록 개편하는 방법이 제안되었습니다.
원문을 나누어 전달해야 하는 문제.¶
대부분의 모델과 마찬가지로, T5도 토큰 길이의 제한이 있습니다. 따라서 긴 문장이나 문서를 전달할 때는 적절히 나누어야 하는데 이는 다음과 같은 문제가 있습니다.
어떻게 나눌 것인가? 그리고 합칠 것인가?¶
일단 문장 단위로 나누기로 하였습니다. 대부분의 경우 큰 문제가 없습니다. 물론 James Joyce의 Ulysses의 경우 4391단어, Jonathan Coe의 The Rotter's Club의 경우 13955단어로 한 문장이 이루어져 있습니다. 이런 작품을 점역한다면 분명 에러가 발생하겠지만, 일단 시연에 사용할 데이터는 이런 경우가 없으므로 이번 iteration에서는 고려하지 않았습니다.
이보다 당면한 문제는, 나눈 것은 합쳐야 한다는 점입니다. 여러 방법이 있을 수 있지만 시연 환경의 특수성을 이용해 업로드 시에 브라우저에서 대기하며 모든 조각이 도착하기를 기다리도록 하였습니다. 안정성을 보장할 수 없으므로 수정되어야 합니다.
추론과 응답¶
얼핏 보기에는 그냥 하나씩 넣으면 되는 것이고 일단 그렇게 구현이 되어있습니다. 그러나 불행히도 시연 수준의 구현이고고 실제로는 대기 중인 모델 인스턴스가 없는지 여부를 확인하고 제어할 필요가 있습니다. (잘못 넣으면 무한히 대기하게 됩니다.) 이 또한 추후 개선될 부분입니다.
ToDos¶
- 접근성 개선: 웹UI를 통한 점역이 아닌, 텔레그램 봇을 통한 점역 서비스로 확장
- PDF 변환 부를 교체할 수 있도록 구조를 개선
- 원문 분할 및 재조합 로직을 개선
- 추론 queue를 관리하는 방법을 개선
- 추론 모델 인스턴스를 관리하는 방법을 개선